ret2reg
利用原理
ret2reg,即返回到寄存器地址进行攻击,可以绕过地址混淆(ASLR)。
一般用于开启ASLR的 ret2shellcode 题型,在函数执行后,传入的参数在栈中传给某寄存器,然而该函数在结束前并未将该寄存器复位,就导致这个寄存器仍还保存着参数,当这个参数是 shellcode 时,只要程序中存在jmp/call reg代码片段时,即可通过 gadget 跳转至该寄存器执行 shellcode。
该攻击方法之所以能成功,是因为函数内部实现时,溢出的缓冲区地址通常会加载到某个寄存器上,在后来的运行过程中不会修改。
只要在函数
ret之前将相关寄存器复位掉,便可以避免此漏洞。
利用思路
主要在于找到寄存器与缓冲区地址的确定性关系,然后从程序中搜索
call reg/jmp reg这样的指令
- 分析和调试程序,查看溢出函数返回时哪个寄存器指向输入缓冲区
- 查找
call reg或jmp reg,将指令所在的地址填充到EIP位置,即返回地址 - 在
reg指向的空间上注入 shellcode
例题
例题:rsp_shellcode
- 源代码
1 | |
- 分析
查保护,没有NX和canary以及PIE保护,即栈可执行。
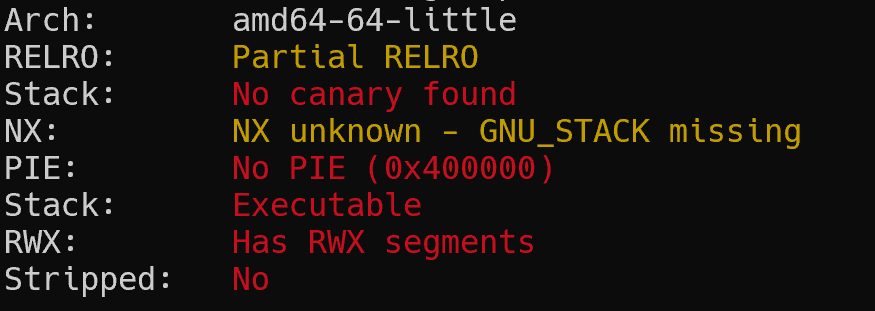
分析源代码发现很明显的栈溢出漏洞,并且溢出字节没有限制。
源代码中还内嵌了一个jmp rsp的汇编指令,猜测要通过 ret2reg 的方式打 shellcode。
gdb 调试发现在函数返回的时候rsp仍然指向输入缓冲区地址。

这样我们可以通过将返回地址覆盖为jmp rsp来让rip指向缓冲区,然后在jmp rsp指令后拼接上 shellcode 让程序执行 shellcode。
可以将 shellcode 拼接在jmp rsp后面是因为程序可以溢出很长的字节,我们可以在填充和jmp rsp的后面直接拼接上 shellcode。但是如果程序溢出长度不满足,那么我们就要通过其它方法了。
- exp
1 | |
例题:X-CTF Quals 2016 - b0verfl0w
- 分析
查保护,32位程序无NX、canary以及PIE保护,栈可执行。
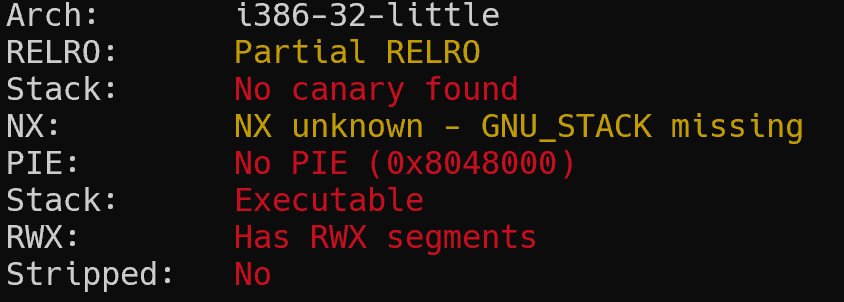
ida反编译分析伪代码。
程序限制读取 50 个字节,所以我们只能溢出 18 个字节。
接下来 gdb 调试一下。
gdb 动调调试发现,在程序返回时esp寄存器仍然指向输入缓冲区。

并且我们通过 ROPgadget 在程序中搜索到了jmp esp指令。

这样很明显可以进行 ret2reg 利用,但是溢出仅仅只有 18 字节,我们无法像上题一样直接在jmp esp后面拼接 shellcode。这里我们就需要换一种方法了。
我们无法直接返回执行很长的 shellcode,但是可以通过构造简短的汇编指令将栈指针进行一个迁移。比如我们将其迁移到 payload 的前部分。这样我们可以直接将 payload 的前部分的填充替换为 shellcode,然后通过 ret2reg 迁移执行。
- exp
1 | |
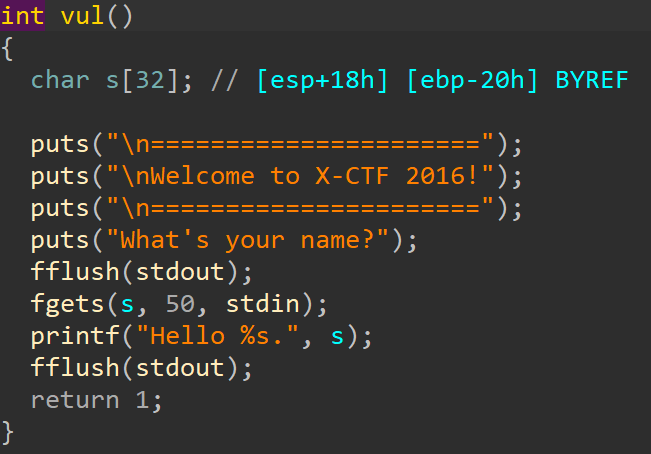
例题:ciscn_2019_s_9
- 分析
查保护发现几乎没保护,可以尝试打 shellcode。
分析main函数,发现关键函数pwn,跟进查看。

分析代码发现,fgets可以向长度为 24 字节的变量s读入 50 个字符,所以存在栈溢出。
溢出字节为 18 个字节。
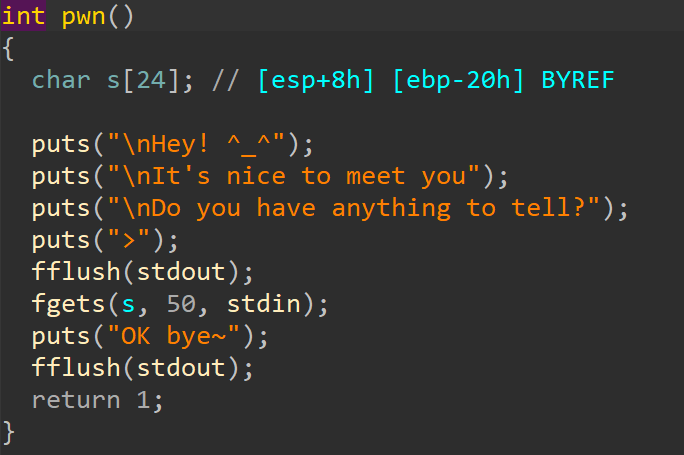
gdb 动态调试发现,在pwn函数返回时esp是指向栈顶的。

而且我们在函数表中发现了jmp rsp指令,所以接下来的思路就很清晰了。
通过 ret2reg打 shellcode。
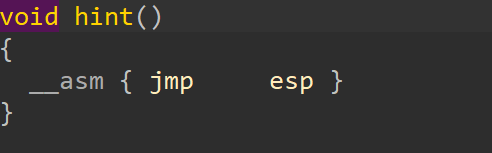
但是我们溢出长度只有 18 个字节,并不足够在jmp esp后拼接上 shellcode。
所以我们仍然要通过简单的汇编指令来将栈帧迁移到 payload 的前部分,然后在 payload 的前部分拼接上我们的 shellcode。
这里使用的是手写的汇编,因为 pwntools 生成的太长了,都超出填充长度了。。。
- exp
1 | |
后言
总结:如果溢出字节足够长就在jmp reg指令后拼接执行 shellcode,如果溢出不够长就构造汇编指令将栈指针迁移到payload 前部分 然后在 payload 前部分拼接上 shellcode 执行。