《CSAPP》chapter2 信息的表示和处理
信息存储
大多数计算机使用8位的块,或者字节(byte),作为最小的可寻址的内存单位,而不是访问内存中单独的位。机器级程序将内存视为一个非常达的字节数组,称为虚拟内存。内存的每个字节都由一个唯一的数字来标识,称为它的地址,所有可能地址的集合就称为虚拟地址空间。
C语言中一个指针的值(无论它指向一个整数、一个结构或是某个其他程序对象)都是某个存储块的第一个字节的虚拟地址。
十六进制表示法
一个字节由8位组成。在二级制表示法中,它的值域是0000000011111111.如果看成十进制整数,它的值域就是0255.
二进制表示法太冗长,而十进制表示法与位模式的互相转化很麻烦。替代的方法是,以16为基数,或者叫做十六进制数,来表示位模式。
十六进制使用数字‘0’‘9’以及字符‘A’‘F’来表示16个可能的值。用十六进制书写,一个字节的值域为00~FF。
在C语言中,以0x或0X开头的数字常量被认为是十六进制的值。
字数据大小
每台计算机都有一个字长,指明指针数据的标称大小。因为虚拟地址是以这样的一个字来编码的,所以字长决定的最重要的系统参数就是虚拟地址空间的最大大小。
大多数64位机器也可以运行为32位机器编译的程序,这时一种向后兼容。
计算机和编译器支持多种不同方式的编码的数字格式,如不同长度的整数和浮点数。
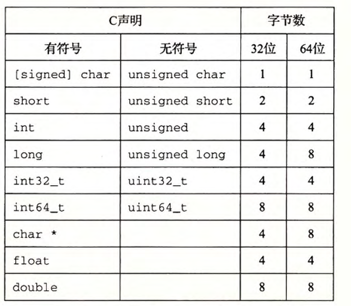
C语言支持整数和浮点数的多种数据格式。
整数或者为有符号的,既可以表示负数、零和正数;或者为无符号的,即只能表示非负数。
为了避免由于依赖典型大小和不同编译器设置带来的奇怪行为,ISO C99引入了一类数据类型,其数据大小是固定的,不随编译器和机器设置而变化。其他就有数据类型int32_t和int64_t,它们分别为4个字节和8个字节。
大部分数据类型都编码为有符号数值,除非有前缀关键字unsigned或对确定大小的数据类型使用了特定的无符号声明。
寻址和字节顺序
对于跨越多字节的程序对象,我们必须建立两个规则:这个对象的地址是什么,以及在内存中如何排列这些字节。在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小的地址。
排列表示一个对象的字节有两个通用的规则。
最低有效位在最前面的方式,称为小端法。
最高有效位在最前面的方式,称为大端法。
大多数Intel兼容机都只用小端模式。
一旦选择了特定操作系统,那么字节序列也就固定下来。
字节序列变得重要的三种情况:
- 首先是在不同类型的机器之间通过网络传送二进制数据时。
- 第二种情况是,当阅读表示整型数据的字节序列时字节顺序也很重要。
- 第三种情况是,当编写规避正常的类型系统的程序时。
在C语言中,可以通过使用强制类型转换或联合来允许以一种数据类型引用一个对象,而这种数据类型与创建这个对象时定义的数据类型不同。大多数应用编程都强烈不推荐这种编码技巧,但是它们对系统级编程来说非常有用,甚至是必需的。
在网络中,字节以大端序进行传输。
表示字符串
C语言中字符串被编码为一个以null(其值为0)字符结尾的字符数组。每个字符都由某个标准编码来表示,最常见的是ASCII字符码。
在使用ASCII码作为字符码的任何系统上都将得到相同的结果,与字节和字大小规则无关。
表示代码
不同的机器类型使用不同的且不兼容的指令和编码方式。
二进制代码很少能在不同机器和操作系统组合之间移植。
计算机系统的一个基本概念就是,从机器的角度来看,程序仅仅只是字节序列。
布尔代数简介
布尔注意到通过将逻辑值TRUE和FALSE编码为二进制值1和0,能够设计出一种代数,以研究逻辑推理的基本原则。
最简单的布尔代数是在二元集合{0,1}基础上的定义。
布尔运算~对应于逻辑运算NOT。
布尔运算&对应于逻辑运算and。
布尔运算|对应于逻辑运算or。
布尔运算^对应于逻辑运算异或。
C语言中的位级表示
|(或)
&(与)
~(非)
^(异或)
确定一个位级表达式的结果最后的方法,就是将十六进制的参数扩展成二进制表示并执行二进制运算,然后再转回十六进制。
C语言中的逻辑运算
||(或)
&&(与)
!(非)
C语言中的移位运算
左移运算
x<<k
x向左移动k位,丢弃最高的k位,并在右端补k个0
右移运算
x>>k
逻辑右移和算术右移。
逻辑右移在左端补k个0,得到的结果是。
算术右移是在左端补k个最高有效位的值,得到的结果是
几乎所有的编译器/机器组合都对有符号数使用算术右移。
对于无符号数,右移必须是逻辑的。
整数表示
在本节中,我们描述用位来编码整数的两种不同的方式:一种只能表示非负数,而另一种能够表示负数、零和正数。
整型数据类型
C语言支持多种整型数据类型——表示有限范围的整数。
根据字节分配,不同的大小所能表示的值的范围是不同的。
- 32位

- 64位

C语言标准定义了每种数据类型必须表示的最小的取值范围。
C和C++都支持有符号(默认)和无符号数。Java只支持有符号数。
无符号数的编码
无符号数采用原码进行编码。
补码编码
用于表示负数值。
表示负数将最高位至一,并且按位取反后加一得到补码。
几乎所有的机器都用补码形式来表示有符号整数。
C库中的文件limits.h定义了一组常量,来限定编译器运行的这台及其的不同整型数据类型的取值范围。
有符号数和无符号数之间的转换
强制类型转换的结果保持位值不变,只是改变了解释这些位的方式。
将无符号类型转换成有符号类型,底层的位表示保持不变。
大多数C语言的实现,处理同样字长的有符号数和无符号数之间相互转换的一般规则是:数值可能会改变,但是位模式不变。
C语言中的有符号数与无符号数
C语言支持所有整型数据类型的有符号和无符号运算。
通常,大多数数字都默认为是有符号的。
C语言允许无符号数和有符号数之间的转换,大多数系统遵循的原则是底层的为表示保持不变。
%u无符号显示 %d有符号显示
当执行一个运算时,如果它的一个运算数是有符号的而另一个是无符号的,那么C语言会隐式地将有符号参数强制类型转换为无符号数,那么C语言会隐式地将有符号参数强制类型转换为无符号数,并假设这两个数都是非负的,来执行这个运算。
这种方法对于标准算术运算来说并无多大差异,但是对于像<和>这样的关系运算符来说,它会导致非直观的结果。
扩展一个数字的位表示
一个常见的运算是在不同字长的整数之间转换,同时又保持数值不变。
要将一个无符号数转换为一个更大的数据类型,我们只要简单地在表示在开头添加0.这种运算被称为零扩展。
要将一个补码数字转换为一个更大的数据类型,可以执行一个符号扩展,在表示中添加最高有效位的值。
将不同大小不同类型的数进行转换时,如short转换为unsigned int。我们先要改变大小,之后再完成从有符号到无符号的转换。
截断数字
假设我们不用额外的位来扩展一个数值,而是减少表示一个数字的位数。
截断一个数字可能会改变它的值——溢出的一种形式。对于一个无符号数,我们可以很容易得出其数值结果。
截断无符号数
将数字超过截断位的值直接丢弃。
截断补码数值
将数字超过截断位的值直接丢弃。并且转换为有符号数
关于有符号数与无符号数的建议
有符号数到无符号数的隐式强制类型转换导致了某些非直观的行为。而这些非直观的特性经常导致程序错误,并且这种包含隐式强制类型转换的细微差别的错误很难被发现。因为这种强制类型转换是在代码中没有明确指示的情况下发生的, 程序员经常忽视了它的影响
java消除了无符号数,只允许有符号数的存在
java的>>>被指定为逻辑右移
0-1等于最大无符号数
2^10 = 10^3
整数运算
无符号加法
如果两个无符号数相加的和超过类型位数可以表达的最大数就会产生溢出。
如:
1 | |
补码加法
正溢出
两个正数相加得到负的结果。
因为位数运算中产生溢出导致向符号位进位,符号位变为1。
例:
1 | |
负溢出
两个负数相加得到正的结果
因为位数运算中产生溢出,导致符号位溢出变为0。
例:
1 | |
补码的非
执行位级补码非的方法是对每一位求补,再对结果加1。由此得到这个数的加法逆元。
任何数值都有自己的加法逆元。
数值加上它的加法逆元结果为0。
无符号乘法
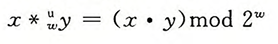
将一个无符号数截断为w位等价于计算该值模2^w。
即截断2w位中的低w位
例:
1 | |
补码乘法
将一个补码数截断为位相当于先计算该值模2^w,再把无符号数转换为补码。
1 | |
乘以常数
在大多数机器上,整数乘法指令相当慢,需要10个或者更多的时钟周期,然而其它整数运算只需要1个时钟周期。
因此编译器做了一项重要的优化,试着用移位和加法运算的组合来代替乘以常数因子的乘法。
例如:
x*2=x<<1
例:
1 | |
除以2的幂
在大多数机器上,整数除法要比整数乘法更慢——需要30个或者更多的时钟周期。
除以 2 的幕也可以用移位运算来实现,只不过我们用的是右移,而不是左移。无符号和补 码数分别使用逻辑移位和算术移位来达到目的。
整数除法总是舍入到零。
除以2的幂的无符号除法
对无符号运算使用移位是非常简单的,部分原因是由于无符号水的右移一定是逻辑右移。
例:12340
| k | >>k | 十进制 | 12340/2^k |
|---|---|---|---|
| 0 | 0011000000110100 | 12340 | 12340.0 |
| 1 | 0001100000011010 | 6170 | 6170 |
| 4 | 0000001100000011 | 771 | 771.25 |
除以2的幂的有符号除法
对于除以2的幂的补码运算来说,情况要稍微复杂一些。首先,为了保证负数仍然为负,移位要执行的是算术右移。
对于x>=0,变量x的最高有效位为0,所以效果与逻辑右移是一样的。因此,对于非负数来说,算术右移k位与除以2^k是一样的。
除以2的幂的补码除法,向下舍入
-12340
| k | >>k | 十进制 | 12340/2^k |
|---|---|---|---|
| 0 | 1100111111001100 | -12340 | 12340.0 |
| 1 | 1110011111100110 | -6170 | -6170.0 |
| 4 | 1111110011111100 | -772 | -771.25 |
关于整数运算的最后思考
正如我们看到的,计算机执行的整数运算实际上是一种模运算形式。表示数字的有限字长限制了可能的值的取值范围,结果运算可能溢出。我们还看到,补码表示提供了 一种既能表示负数也能表示正数的灵活方法,同时使用了与执行无符号算术相同的位级实现,这些运算包括像加法、减法、乘法,甚至除法,无论运算数是以无符号形式还是以补码形式表示的,都有完全一样或者非常类似的位级行为。
浮点数
计算机内部表示实数的方法
二进制小数
理解浮点数的第一步是考虑含有小数值的二进制数字。
浮点主要通过移动二进制小数点来表示尽可能大的取值范围。
IEEE浮点数
(-1)^s M 2^E
- 符号位 s确定了该数字是负数还是正数
- 尾数 M通常是介于1和2之间的小数
- 指数(阶码)E会以2的E次幂形式扩大或缩小尾数值

exp是指数域,它编码了E。
编码表示的值与E的值不同,它只是编码了E
frac是尾数字段,它编码了M
指数E被解释为以偏置形式表示,所以指数E的实际值为exp-bias。
偏移值bias=2^(k-1)-1,其中k是阶码域的位数。
所以float指数偏移为bias=127,double是bias=1023
指数E的值是无符号EXP值减去偏置值bias
将M规格为1.xxxx,我们相应地调整指数(来进行规格化)
例:如果我们要表示100.01,我们将小数点左移使之成为1.00。然后我们调整指数来表示这种位移
尾数域xxxx中的位是二进制小数点右边的所有数字。
浮点数不止可以用来编码实数,也可以用来编码整数
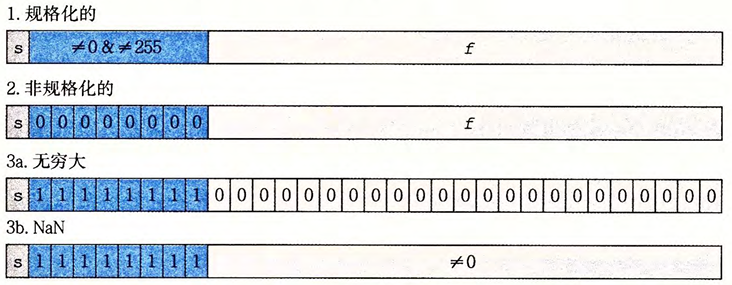
浮点数有三种情况,其中阶码的值决定了这个属于哪一类。
当阶码字段的二进制位不全为0,且不全为1时,此时表示的是规格化的值。
当阶码字段的二进制位全为0时,此时表示的是非规格化的值。
当阶码字段的二进制位全为1时,表示的数值为特殊值。
特殊值有两类,一类表示无穷大或无穷小,另外一类表示不是一个数。
你的笔记已经涵盖了浮点数的各种情况,下面是对这三种情况的详细补充和完善,以帮助你更全面地理解浮点数的表示。
情况1:规格化的值
在浮点数的规格化表示中,满足以下条件:
- 指数(exp)字段的位模式不全为0(表示数值为0);
- 指数字段的位模式不全为1(表示特殊数值)。
在这种情况下,阶码字段解释为偏置形式的有符号整数:
- [ E = e - \text{Bias} ]
- 其中,( e ) 是无符号数,单精度浮点数的偏置为127,双精度浮点数的偏置为1023。
因此,指数的取值范围为:
- 单精度浮点数:[-126, +127]
- 双精度浮点数:[-1022, +1023]
小数字段(frac)用于表示一个范围在[0, 1) 的数值,二进制小数点位于最高有效位(MSB)左侧。尾数(M)定义为:
- [ M = 1 + f ]
这种表示方式常称为“隐含的以1开头的表示”,因为小数部分 ( f ) 之后会隐含一个1。
情况2:非规格化的值
当阶码域全为0时,表示非规格化值。在这种情况下:
- 指数值 ( E ) 被计算为:
- [ E = 1 - \text{Bias} ]
- 尾数(M)由小数字段(frac)直接给出:
- [ M = f ]
非规格化值的存在使得可以表示非常小的数,尤其是接近于0的数。这种表示方式允许浮点数的表示更为连续,尤其在极小数值时,防止了“下溢”的问题。
情况3:特殊值
特殊值包括:
零:当exp和frac均为0时,表示正零或负零。正零的符号位为0,负零的符号位为1。
- 例如,
0 00000000 00000000000000000000000表示正零,1 00000000 00000000000000000000000表示负零。
- 例如,
无穷大:当exp全为1,frac全为0时,表示正无穷大或负无穷大。正无穷大符号位为0,负无穷大符号位为1。
- 例如,
0 11111111 00000000000000000000000表示正无穷大,1 11111111 00000000000000000000000表示负无穷大。
- 例如,
非数(NaN):当exp全为1且frac不全为0时,表示非数(Not a Number)。这通常在计算错误时产生,如0除以0的情况。
- 例如,
0 11111111 10000000000000000000000是一个NaN值。
- 例如,
数字示例
在IEEE 754标准中,浮点数的表示形式包括符号位、指数部分和尾数部分。您提供的数字示例可以详细说明这一点。
- 原始整数:
15213 - 二进制表示:
11101101101101 - 标准化形式: ( 1.1101101101101 \times 2^{13} )
在这里,( M = 1.1101101101101 ) 是尾数,frac 是尾数去掉“1.”后面的部分,补齐为23位:
frac:
11011011011010000000000指数:
- 原始指数 ( E = 13 )
- 偏移量 ( \text{bias} = 127 )
- 编码后的指数: ( \text{exp} = 127 + 13 = 140 )
- 二进制表示: ( 140 = 10001100 )
因此,编码后的结果为:
1 | |
舍入
在浮点数表示中,舍入是确保数值精度的重要过程。根据IEEE 754标准,通常采用向偶数舍入的方法,即当尾数的最后一位为1时,如果其前面的位是0,直接舍去;如果有1存在,则需要向上舍入。通过这种方式,可以减少长期的舍入误差。
浮点运算
浮点运算的基本原则包括:
- 对齐:在执行运算之前,尾数需要对齐。通常,会根据指数的大小调整尾数,使得它们具有相同的指数。
- 计算:在尾数相同的情况下,直接进行加减法运算。
- 归一化:结果可能需要归一化,以确保符合标准的浮点数格式。
- 舍入:在结果计算完成后,应用舍入规则。
C语言中的浮点数
在C语言中,浮点数的类型主要包括 float 和 double:
float: 单精度浮点数,通常采用32位表示(1位符号位、8位指数、23位尾数)。double: 双精度浮点数,通常采用64位表示(1位符号位、11位指数、52位尾数)。
在支持IEEE 754浮点格式的机器上,这些类型直接对应于单精度和双精度浮点。C语言中的浮点数计算通常遵循向偶数舍入的规则,确保在大量运算中保持精度。