简介
传统的 AFL、libFuzzer 和 honggfuzz 主要支持用 C/C++ 语言开发的项目。但是现在随着 Rust、Go 等新兴编译型语言的兴起,相应的出现了对这些语言开发的项目进行 Fuzzing 的需求。因此,人们在基于传统的 Fuzz 工具的基础上,逐步为这些语言构建了 Fuzz 工具。
对 Go 程序的 Fuzz 工具有官方提供的 go test fuzz 和第三方的 go-fuzz。但是现在 go-fuzz 已经停止维护,作者表示不再维护 go-fuzz 并建议大家使用 go test -fuzz。
Go官方团队的 go test fuzz 实现借鉴了 go-fuzz 的设计思想,Go 1.18 版本把 Fuzzing 整合到了go test工具链和testing包里。go-fuzz 基于 AFL/libFuzzer 的变异策略,而 go test 使用的是自研的变异算法。
本文学习的正是如何使用 go test -fuzz。
Fuzz流程
基础实例
下面是官方模糊测试的示例,突出显示了其主要的组件。
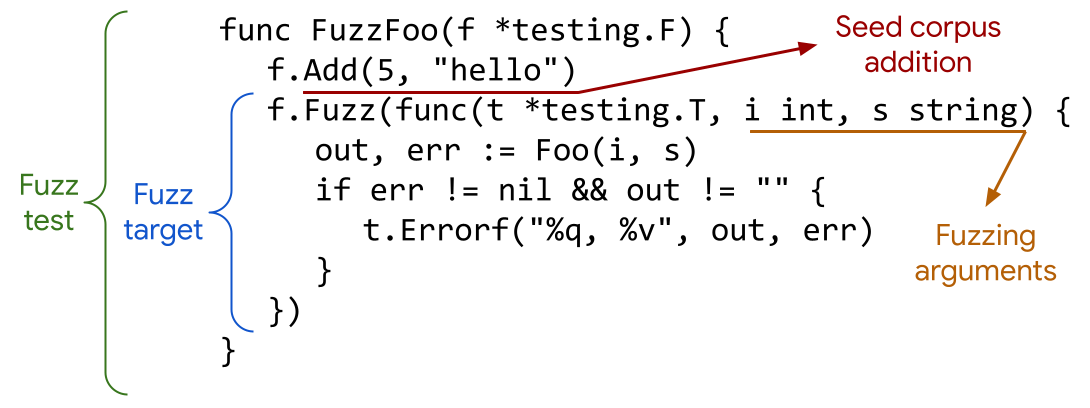
使用 go test fuzz,首先需要创建一个以_test.go结尾的测试文件。然后我们需要编写它的测试入口函数,要求必须以Fuzz字段开头。然后通过f.Add指定初始种子,然后通过f.Fuzz的s参数进行数据的投喂。
package fuzz
import (
"testing"
"net/url"
)
func FuzzParseURL(f *testing.F) {
f.Add("https://example.com") // 种子输入
f.Fuzz(func(t *testing.T, s string) {
if _, err := url.Parse(s); err != nil { //目标函数
t.Skip() // 忽略无效输入
}
})
}
编写测试文件我们必须遵循以下规则:
- 测试函数必须命名为
FuzzXXX格式,仅接受*testing.F参数,无返回值。 - 测试代码必须位于
*_test.go文件中才能执行。 - 测试目标必须是通过
(*testing.F).Fuzz调用的方法,第一个参数为*testing.T,后接模糊参数,无返回值。 - 每个文件只能有一个测试目标。
- 所有种子语料条目必须与模糊参数类型完全匹配且顺序一致(适用于
(*testing.F).Add调用和testdata/fuzz目录中的语料文件)。
我们可以直接使用f.Add来添加种子用例,但是如果我们想要将文件添加为种子则需要自己实现这部分代码。
package fuzz
import (
"bytes"
"os"
"testing"
"net/url"
)
func FuzzParseURL(f *testing.F) {
if data, err := os.ReadFile("/corpus/url.txt"); err == nil {
f.Add(data)
}
f.Add("https://example.com") // 种子输入
f.Fuzz(func(t *testing.T, s string) {
if _, err := url.Parse(s); err != nil {
t.Skip() // 忽略无效输入
}
})
}
Fuzzing
通过-fuzz参数指定要测试的目标函数名开始模糊测试。
#初始包
go mod init fuzz_url
go mod tidy
# 运行模糊测试(默认会无限运行)
go test -fuzz=FuzzParseURL
常用参数:
-fuzz: 指定要运行的模糊测试函数名。-fuzztime:设置运行持续时间(如 “10s”、“1h”,默认为无限)。-fuzzminimizetime:最小化崩溃用例的时间(默认60秒,0表示禁用)。-parallel:并行进程数(默认GOMAXPROCS)
默认情况下,每个种子语料条目都会作为单元测试执行。启用模糊测试后,匹配的测试会持续运行直到发现 crash 为止。
Crash分析
当出现以下情况会触发 crash:
- 代码或测试发生panic
- 调用
t.Fail等失败方法 - 不可恢复错误(如os.Exit)
- 执行超时(默认1秒)
crash 时会自动最小化输入并保存到testdata/fuzz/目录,可作为回归测试用例。
通过运行目标函数可以复现 crash:
go test -run=FuzzParseURL
然后通过分析 crash 的调用栈,可以定位到漏洞函数部分。
案例
Out-of-Bounds Panic in model.skipStringLit due to Missing Bounds Check · Issue #1193 · pdfcpu/pdfcpu
本案例是笔者对 pdfcpu 做的一个简单测试,下面简单讲解一下测试流程。
首先需要对目标进行一个简单的了解,比如本案例的目标是一个 pdf 的解析库,那么要了解它的相关的库函数有哪些,哪些是具体的解析函数,从而来了解我们需要测试的接口。
比如本例中的bytes.NewReader函数用于解析 PDF 文件,model.NewDefaultConfiguration用于获取默认配置,最后调用api.Validate对 PDF 文件进行解析,具体的测试目标就是api.Validate。
创建 fuzzer 文件pdf_test.go:
package fuzz
import (
"bytes"
"os"
"testing"
"github.com/pdfcpu/pdfcpu/pkg/api"
"github.com/pdfcpu/pdfcpu/pkg/pdfcpu/model"
)
func FuzzPDF(f *testing.F) {
if data, err := os.ReadFile("/root/corpus/pdf/pdf.pdf"); err == nil {
f.Add(data)
}
f.Fuzz(func(t *testing.T, data []byte) {
r := bytes.NewReader(data)
conf := model.NewDefaultConfiguration()
_ = api.Validate(r, conf)
})
}
运行:
go test -fuzz=FuzzPDF
很快 fuzzer 就 crash 掉了,笔者根据 crash 信息编写了一个最小的复现代码:
package main
import (
"bytes"
"fmt"
"github.com/pdfcpu/pdfcpu/pkg/api"
"github.com/pdfcpu/pdfcpu/pkg/pdfcpu/model"
)
func main() {
data := []byte("%PDF-1.0stream\n0000")
r := bytes.NewReader(data)
conf := model.NewDefaultConfiguration()
if err := api.Validate(r, conf); err != nil {
fmt.Printf("Validation error: %v\n", err)
} else {
fmt.Println("Validation succeeded.")
}
}
根据崩溃堆栈来分析 crash 的原因:
panic: runtime error: slice bounds out of range [-1:]
goroutine 1 [running]:
github.com/pdfcpu/pdfcpu/pkg/pdfcpu/model.skipStringLit({0xc0001a9c00?, 0xf9c8e8?}, 0xc0001a9c00?, 0x400?, 0x0?, 0xc0001a9c00?)
/root/.local/go/pkg/mod/github.com/pdfcpu/pdfcpu@v0.11.0/pkg/pdfcpu/model/parse.go:1273 +0xd4
github.com/pdfcpu/pdfcpu/pkg/pdfcpu/model.skipCommentOrStringLiteral({0xc0001a9c00?, 0x400?}, 0xf9c8e8?, 0x1?, 0x1299540?, 0xc0001a9c00?, 0x0?)
/root/.local/go/pkg/mod/github.com/pdfcpu/pdfcpu@v0.11.0/pkg/pdfcpu/model/parse.go:1302 +0x65
github.com/pdfcpu/pdfcpu/pkg/pdfcpu/model.DetectKeywordsWithContext({0xfa59b8, 0x12b9280}, {0xc0001a9c00?, 0x400?})
/root/.local/go/pkg/mod/github.com/pdfcpu/pdfcpu@v0.11.0/pkg/pdfcpu/model/parse.go:1349 +0x1b7
github.com/pdfcpu/pdfcpu/pkg/pdfcpu.buffer({0xfa59b8, 0x12b9280}, {0xfa1c80, 0xc0001b0ae0})
/root/.local/go/pkg/mod/github.com/pdfcpu/pdfcpu@v0.11.0/pkg/pdfcpu/read.go:1752 +0x191
github.com/pdfcpu/pdfcpu/pkg/pdfcpu.parseXRefStream({0xfa59b8, 0x12b9280}, 0xc00027a900, {0xfa1c80?, 0xc0001b0ae0?}, 0xc00019da08, 0x0, 0x1)
/root/.local/go/pkg/mod/github.com/pdfcpu/pdfcpu@v0.11.0/pkg/pdfcpu/read.go:696 +0x132
github.com/pdfcpu/pdfcpu/pkg/pdfcpu.buildXRefTableStartingAt({0xfa59b8, 0x12b9280}, 0xc00027a900, 0xc00019da08)
/root/.local/go/pkg/mod/github.com/pdfcpu/pdfcpu@v0.11.0/pkg/pdfcpu/read.go:1606 +0x3c9
github.com/pdfcpu/pdfcpu/pkg/pdfcpu.readXRefTable({0xfa59b8, 0x12b9280}, 0xc00027a900)
/root/.local/go/pkg/mod/github.com/pdfcpu/pdfcpu@v0.11.0/pkg/pdfcpu/read.go:1643 +0x12e
github.com/pdfcpu/pdfcpu/pkg/pdfcpu.ReadWithContext({0xfa59b8, 0x12b9280}, {0xfa34c8?, 0xc0001abc20?}, 0xc000035dd0?)
/root/.local/go/pkg/mod/github.com/pdfcpu/pdfcpu@v0.11.0/pkg/pdfcpu/read.go:107 +0x1a5
github.com/pdfcpu/pdfcpu/pkg/pdfcpu.Read(...)
/root/.local/go/pkg/mod/github.com/pdfcpu/pdfcpu@v0.11.0/pkg/pdfcpu/read.go:78
github.com/pdfcpu/pdfcpu/pkg/api.ReadContext({0xfa34c8?, 0xc0001abc20?}, 0x120?)
/root/.local/go/pkg/mod/github.com/pdfcpu/pdfcpu@v0.11.0/pkg/api/api.go:74 +0x9f
github.com/pdfcpu/pdfcpu/pkg/api.Validate({0xfa34c8, 0xc0001abc20}, 0xc0001d3f40?)
/root/.local/go/pkg/mod/github.com/pdfcpu/pdfcpu@v0.11.0/pkg/api/validate.go:44 +0x9a
main.main()
/root/project/pdfcpu/demo.go:17 +0xb9
exit status 2
根据崩溃的堆栈信息我们轻易得知这是由于越界访问而导致的崩溃。之后我们通过自底向上的一步步跟踪,可以得知崩溃实际触发在model.skipStringLit函数中。
进一步分析后发现根本原因是由于skipStringLit 没有做边界检查,导致在查找比括号是使用了bytes.IndexByte,当输入缺少闭括号时返回 -1,然后被直接用在切片操作,导致了越界访问。
我们也可以直接将 Crash 的堆栈信息丢给 AI,让 AI 给我们分析 Crash 原因。
参考
dvyukov/go-fuzz:Go 的随机测试 dvyukov/go-fuzz-corpus:github.com/dvyukov/go-fuzz 示例的语料库 使用 Go-Fuzz 进行模糊测试 |💻 |博客 教程:模糊测试入门 - Go 编程语言 Learning Go-Fuzz 2: goexif2