简介
libFuzzer 是一个基于覆盖率引导的进化模糊测试引擎,旨在通过代码覆盖优化输入数据,从而发现潜在的程序漏洞。libFuzzer 以库的形式链接到目标代码中,专门用于测试指定的目标函数。通过动态地将 fuzz 输入提供给目标函数,libFuzzer 能够有效地引导测试过程,优化覆盖的路径,并且通常用于 C/C++ 项目的单元测试。
libFuzzer 通过与被测试的目标链接,向入口函数提供测试的输入。模糊测试引擎通过追踪代码覆盖的区域来工作,并对输入数据进行变异,以最大化代码的覆盖率。libFuzzer 通过 LLVM 的 SanitizerCoverage 插件来获取代码覆盖信息。需要注意的是,模糊测试的目标与 libFuzzer 本身无关,因此可以将其与其他模糊测试引擎(如 AFL 或 Radamsa)结合使用,以增强测试效果。
libFuzzer 基于 LLVM 项目实现,是一个编译好的链接库,特别适用于有源代码的程序,且程序已经设计了能够处理 fuzz 输入的接口。实现代码在llvm-project/compiler-rt/lib/fuzzer目录下。
接口函数
LibFuzzer 不是对整个程序进行模糊测试,而是测试一个格式为如下签名的函数:
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size);
我们需要自己实现这个函数,LibFuzzer 会不断调用它,并提供不同的Data和Size。
libFuzzer以LLVMFuzzerTestOneInput()作为用户自定义的模糊测试入口点,用户只需要关注为 libFuzzer 生成的数据编写接口调用逻辑,而 libFuzzer 会通过自己实现的数据生成和变异逻辑来进行 fuzz。
环境搭建
clang 6.0 及更高版本已经包含了 libFuzzer,因此我们只需要安装 clang 即可。
apt install clang llvm
基本使用
这里我们通过 libFuzzer work 中的示例来学习如何编写 libFuzzer 的 fuzzer。
目标函数
使用 libFuzzer 的第一步是实现一个模糊目标(fuzz target),这是一个接受字节数组并通过被测试的 API 执行某些操作的函数。代码示例如下:
vuln就是我们需要测试的目标函数,接下来我们需要给它编写测试的 fuzzer。
#include <stdint.h>
#include <stddef.h>
bool vuln(const uint8_t* data, size_t size) {
bool result = false;
if (size >= 3) {
result = data[0] == 'F' &&
data[1] == 'U' &&
data[2] == 'Z' &&
data[3] == 'Z';
}
return result;
}
编写fuzzer
这里只需要将要测试的函数添加即可。
#include <stdint.h>
#include <stddef.h>
#include "vuln.h"
//通过接口将数据投喂到目标函数
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
vuln(data, size);
return 0;
}
Fuzzing
编译:
clang++ -fsanitize=address,fuzzer fuzzer.cc -o fuzzer
-fsanitize=fuzzer:启用 LibFuzzer-fsanitize=address:启用 ASan 检测内存错误
配置语料:
创建一个空目录用于存放初始语料,并运行 fuzzer 程序。libFuzzer 会递归遍历指定的目录,读取所有文件作为初始输入。
mkdir corpus
echo "a" > corpus/seed
开始 Fuzzing:
运行 Fuzzer 程序即可进行 Fuzz。
./fuzzer corpus
crash分析
程序崩溃之后会在当前目录下生成 crash 文件,可以看到以下 crash 文件内容是FUZ。

我们可以直接通过 fuzzer 指定 crash 文件来复现 crash。
./fuzzer ./crash-0eb8e4ed029b774d80f2b66408203801cb982a60
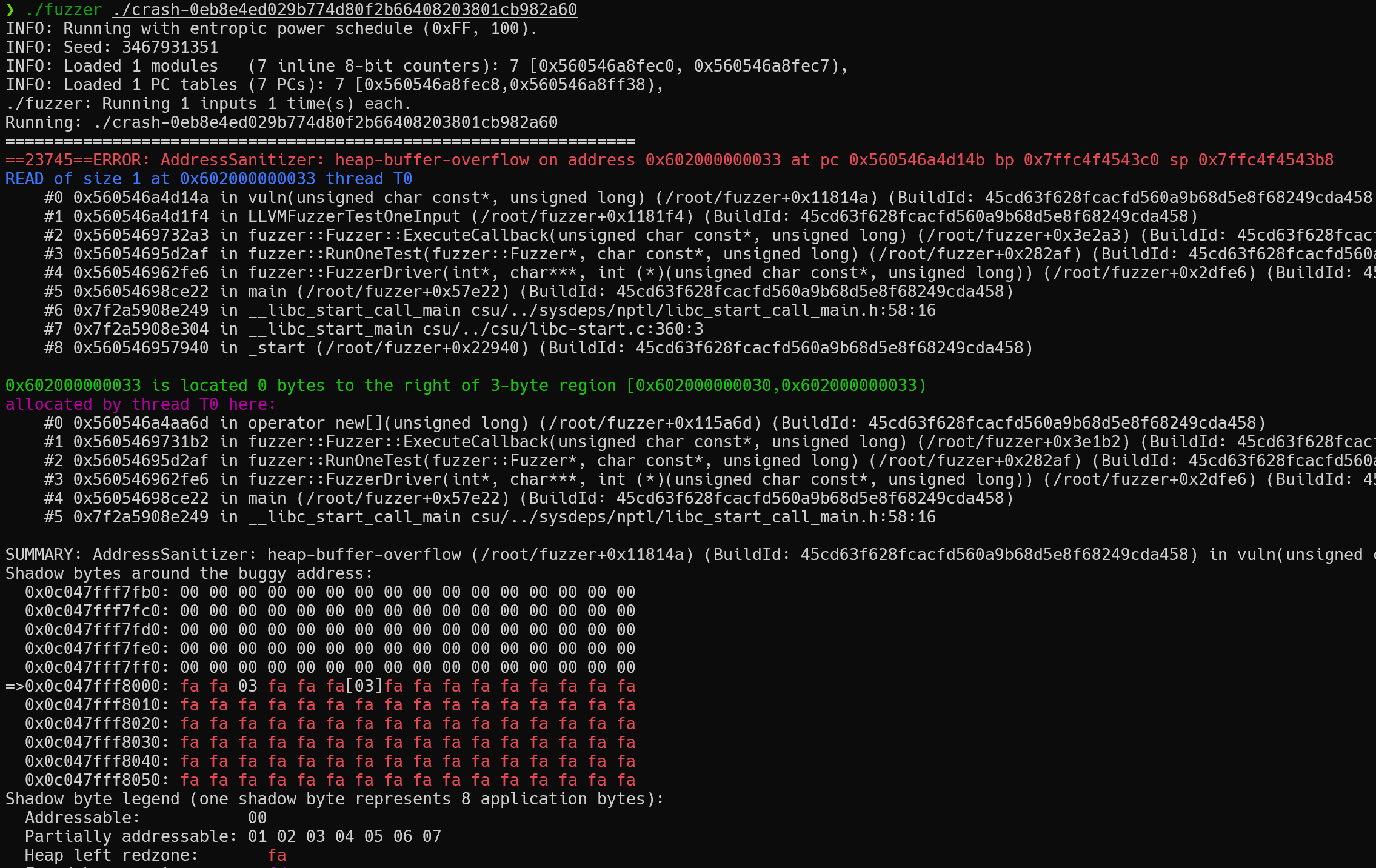
ASan 会显示出当前 crash 的堆栈信息。
我们还可以通过symbolize=1启用堆栈跟踪的符号化解析,将二进制地址转换为可读的代码位置(如函数名、源文件行号)。
ASAN_OPTIONS=symbolize=1 ./fuzzer ./crash-0eb8e4ed029b774d80f2b66408203801cb982a60
更多参数:
-max_total_time:设置最大运行时间-print_final_stats:打印最终统计信息-seed=N:设置随机种子,默认值为 0。-runs=N:设置测试运行次数,默认为 -1(无限次运行)。-max_len=N:设置输入最大长度,默认值为 0。-timeout=N:设置超时秒数,默认 1200 秒。-rss_limit_mb=N:设置内存限制,默认 2048 MB。-reload:如果为 1,模糊器定期重新加载种子目录。
语料库优化
当拥有一个大型语料库时,我们可能希望进行语料库最小化或合并操作,以确保覆盖范围的完整性,同时减小语料库的规模。使用-merge=1参数,可以将新的输入合并到现有语料库中,仅保留能触发新路径的输入。
合并语料库
合并两个语料库:
mkdir corpus1 # 存储最小化后的语料库
./fuzzer -merge=1 corpus1 corpus2
这会将 corpus2 中的种子合并到 corpus1,只保留哪些可以触发新路径的种子。
合并恢复
合并恢复是 libFuzzer 提供的一种中断恢复机制。在执行语料库合并时,如果因某些原因(如崩溃、系统中断或人为终止)导致合并未能完成,合并恢复允许从中断的地方继续合并,而无需从头开始。
- 初始化合并
首先,使用以下命令开始合并两个语料库,并指定一个控制文件来记录合并的状态:
./fuzzer corpus1 corpus2 -merge=1 -merge_control_file=SomeLocalPath
参数-merge_control_file=SomeLocalPath用于指定保存合并状态的文件路径。
- 处理合并中断
如果合并进程中断,可以通过执行以下命令来恢复合并:
killall -SIGUSR1 fuzzer
该命令会将合并状态保存到指定的控制文件,以便下一次恢复时可以继续从上次中断的地方进行合并,而无需从头开始。
- 恢复合并
合并过程中断可以通过以下命令恢复合并:
killall -SIGUSR1 fuzzer
这会使 fuzzer 从中断的位置继续合并,而不是重新开始。
字典支持
字典构成:
字典每一行都是一个可被插入、替换或拼接到输入中的字符串或字节片段。在 Fuzz 过程中
用双引号包裹,特殊字符需要转义。
"GET"
"POST"
"Content-Type:"
"username="
"{\"key\":"
"\r\n"
使用字典:
通过-dict参数指定使用的字典。
./fuzzer corpus -dict=demo.dict
并行模式
每个 libFuzzer 进程都是单线程的,除非受测库启动它自己的线程。然而,可以通过并行运行多个实例并共享一个语料库目录来实现并行模糊测试。这样做的好处是,任何一个模糊测试进程发现的输入将能够供其他进程使用(除非使用了-reload=0禁用此功能)。
libFuzzer 支持多进程或多线程方式的并行模糊测试。你可以通过设置多个实例来运行 libFuzzer,每个实例都有自己的输入 Corpus,并且共享一个全局结果。以下是并行模糊测试的常用配置选项:
./fuzzer -jobs=10 corpus
选项说明:
-jobs=N:设置要运行的模糊测试作业数量。这决定了并行运行的模糊测试实例数。每个作业将会在不同的进程中运行,并且共享语料库,直到达到时间/迭代限制或找到错误;-workers=N:设置并行工作的进程数。这可以覆盖-jobs的默认值。即使是一个多核 CPU,libFuzzer 默认只使用一半的核心数来运行模糊测试。如果你有12核机器,可以通过-workers=12来使用所有的核心来加速模糊测试过程。
Fork模式
libFuzzer 默认在单进程模式下运行,而 Fork 模式通过多子进程与父进程的配合来执行模糊测试。使用 Fork 模式可以提升模糊测试的容错性,特别是在处理内存溢出、超时和崩溃时。Fork 模式通常用于大规模模糊测试时,可以通过独立的子进程来并行化测试。
参数说明:
-fork=N:启用 Fork 模式,开启 N 个子进程并行 fuzz。父进程负责协调语料、调度和崩溃合并;-jobs=N:并行作业数量。与-workers配合使用,推荐用于分布式 / CI 等现代调度场景;-workers=N:每个工作进程中使用的线程数;-ignore_ooms=1:如果子进程发生内存溢出,继续 fuzz 并保存问题输入;-ignore_timeouts=1:如果子进程超时,继续 fuzz 并保存问题输入;-ignore_crashes=0:默认遇到崩溃会中止 fuzz,可设置为 1 忽略并继续。
使用 Fork 模式,启动 4 个子进程并忽略崩溃:
./fuzzer -fork=4 corpus -ignore_crashes=1
使用并行模式,启动 4 个作业,每个作业有 1 个工作线程,并忽略崩溃:
./fuzzer -jobs=4 -workers=1 corpus -ignore_crashes=1
覆盖率分析
LibFuzzer 使用 基于 SanitizerCoverage(SanCov) 的插桩方式记录哪些代码路径已经被执行过。它依赖 LLVM 编译器提供的功能,在编译时插入探针代码,以便在运行时收集覆盖率信息。
clang++ -fsanitize=fuzzer -fsanitize-coverage=trace-pc-guard -g fuzzer.cc -o fuzzer
-fsanitize=fuzzer:启用 libFuzzer 驱动;-fsanitize-coverage=trace-pc-guard:在每个基本块插入 PC 路径追踪代码;
每当 Fuzzer 执行一次输入,它会:
- 收集当前输入触发的路径哈希;
- 判断是否是新的路径;
- 如果是新路径,将该输入加入语料库。
收集覆盖率信息:
通过LLVM_PROFILE_FILE环境变量指定覆盖率数据的输出文件。
LLVM_PROFILE_FILE="coverage.profraw" ./fuzzer corpus/
合并 Profile 数据:
执行完 fuzzer 后,使用llvm-profdata工具合并收集到的 profile 数据。
llvm-profdata merge -sparse coverage.profraw -o coverage.profdata
生成可读的覆盖率报告:
llvm-cov show ./fuzzer -instr-profile=coverage.profdata fuzzer.cc
生成 HTML 报告:
llvm-cov show ./fuzzer -instr-profile=coverage.profdata -format=html -output-dir=coverage_html
案例
复现著名的心脏滴血漏洞。
构建项目
#下拉项目
git clone https://github.com/google/fuzzer-test-suite.git
cd fuzzer-test-suite
./openssl-1.0.1f/build.sh
cd BUILD
编写fuzzer
以下代码通过 libFuzzer 对 OpenSSL 的 SSL 握手过程进行测试。在每次测试中,通过 fuzzer 提供的不同数据,模拟与 SSL/TLS 握手发现相关的安全漏洞。
#include <openssl/ssl.h>
#include <openssl/err.h>
#include <assert.h>
#include <stdint.h>
#include <stddef.h>
#ifndef CERT_PATH
# define CERT_PATH
#endif
// OpenSSL 初始化
SSL_CTX *Init() {
SSL_library_init(); //初始化 OpenSSL库
SSL_load_error_strings(); //加载 OpenSSL 错误字符串
ERR_load_BIO_strings(); //加载 BIO 相关的错误字符串
OpenSSL_add_all_algorithms(); //加载 OpenSSL 支持的所有加密算法
SSL_CTX *sctx; //创建 SSL 上下文
assert (sctx = SSL_CTX_new(TLSv1_method()));
assert(SSL_CTX_use_certificate_file(sctx, CERT_PATH "server.pem", SSL_FILETYPE_PEM));//加载公钥证书
assert(SSL_CTX_use_PrivateKey_file(sctx, CERT_PATH "server.key",SSL_FILETYPE_PEM)); //加载私钥文件
return sctx;
}
//Fuzz 入口
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) {
static SSL_CTX *sctx = Init(); //初始化 SSL 库
SSL *server = SSL_new(sctx); //创建 SSL 对象
BIO *sinbio = BIO_new(BIO_s_mem()); //创建 BIO 对象
BIO *soutbio = BIO_new(BIO_s_mem()); //创建 BIO 对象
SSL_set_bio(server, sinbio, soutbio); //绑定 BIO 对象到 SSL 对象
SSL_set_accept_state(server); //设置 SSL 状态为接受状态
BIO_write(sinbio, Data, Size); //将数据写入输入 BIO
SSL_do_handshake(server); //执行 SSL 握手
SSL_free(server); //释放 SSL 对象
return 0;
}
编译:
clang++ -g openssl_fuzzer.cc -O2 -fno-omit-frame-pointer -fsanitize=address,fuzzer \
-fsanitize-coverage=trace-cmp,trace-gep,trace-div \
-Iopenssl1.0.1f/include openssl1.0.1f/libssl.a openssl1.0.1f/libcrypto.a \
-o openssl_fuzzer
Fuzzing
fuzzer 要求公钥和私钥文件和它在一个目录下。
#将证书等文件复制到当前目录
cp ../openssl-1.0.1f/runtime/* ./
#配置语料
echo "aa" > ./corpus/seed
#开始fuzzing
./openssl_fuzzer -max_total_time=300 -detect_leaks=0
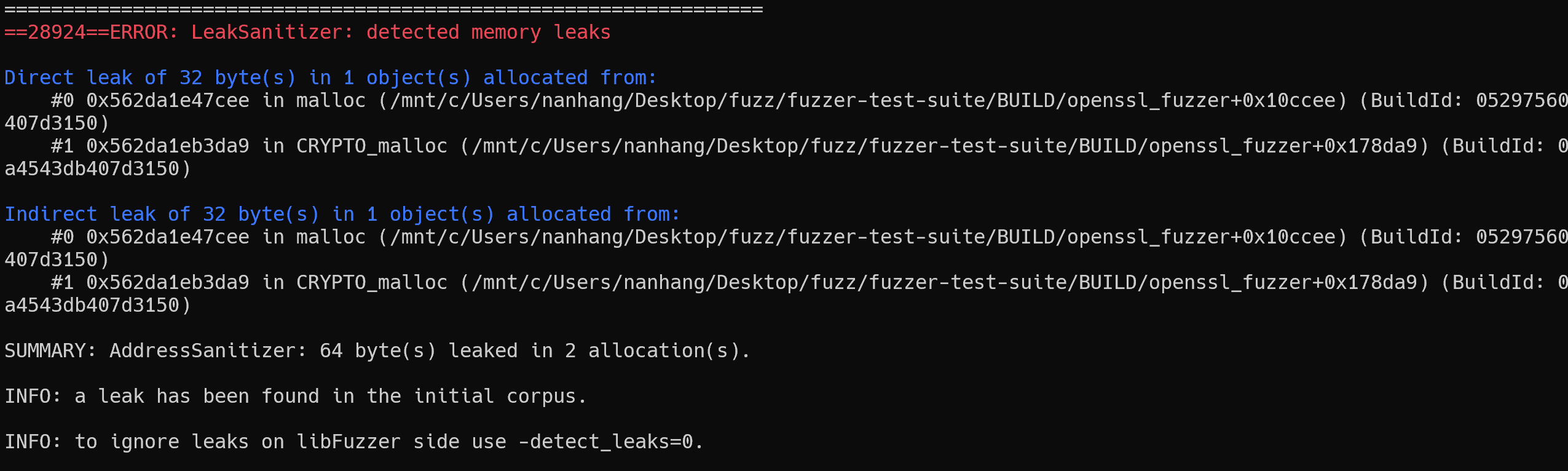
Crash分析
分析 crash 信息之后,发现 crash 原因为在调用CRYPTO_malloc()分配 32 字节内存,但是没有释放。
后言
libFuzzer 可以和 AFL 联合加快 Fuzz 效率。比如先用 AFL 进行初步的 Fuzz 测试,使用 AFL 生成的样本进行 libFuzzer 测试。对目标函数进行专注性的模糊测试。
Reference
Dor1s/libfuzzer-workshop: Repository for materials of “Modern fuzzing of C/C++ Projects” workshop. libFuzzer 官方文档 [原创]libFuzzer模糊测试引擎调研与自定义开发 fuzz实战之libfuzzer - SecPulse.COM | 安全脉搏 libFuzzer漏洞挖掘总结教程 - FreeBuf网络安全行业门户 google/fuzzer-test-suite: Set of tests for fuzzing engines