无名侠师傅课程的学习笔记
简介
什么是 LLM
LLM 是一种擅长理解和生成人类语言的 AI 模型。他们接受了大量文本数据的训练,使他们能够学习语言的模式、结构甚至细微差别。
如今,大多数 LLM 都基于 Transformer 架构构建,这是一种基于 “Attention” 算法的深度学习架构,于 2018 年 Google 发布 BERT 以来,该架构引起了人们的极大兴趣。
什么是 Agent
Agent 定义上是一个:能够推理、规划并与环境交互的 AI 模型。一旦他有了计划,他就必须采取行动。为了执行他的计划,他可以使用他知道的工具列表中的工具。
将大语言模型想象成一个大脑,大脑可以进行思考和决策,然后交给四肢去执行。单纯的大脑是做不了什么的,所以我们需要给大预言模型添加四肢,而工具代码就是它的四肢。
所以 Agent 主要有两部分组成:
- 大脑(LLM):LLM 处理推理和规划。它根据情况决定要采取哪些行动。
- 身体(功能和工具):可以做哪些事情在于有哪些功能和工具。例如,人类没有翅膀,所以不能飞行。
根据这个定义,Agent 存在于一个不断增加的代理范围内:
| 代理级别 | 描述 | 这叫什么 | 示例模式 |
|---|---|---|---|
| ☆☆☆ | 代理输出对程序流程没有影响 | 简单的处理器 | process_llm_output(llm_response) |
| ★☆☆ | 代理输出决定基本控制流 | 路由器 | if llm_decision(): path_a() else: path_b() |
| ★★☆ | 代理输出决定函数执行 | 工具调用方 | run_function(llm_chosen_tool, llm_chosen_args) |
| ★★★ | 代理输出控制迭代和程序继续 | 多步骤代理 | while llm_should_continue(): execute_next_step() |
| ★★★ | 一个代理工作流可以启动另一个代理工作流 | 多代理 | if llm_trigger(): execute_agent() |
什么是工具
工具调用(Tool Calling)就是 LLM 的四肢,通过工具调用大模型可以从外界获取信息,也可以向外界发送信息。
Tool Calling 是一种机制,允许 LLM 在对话过程中,判断是否需要调用外部工具,并构造符合要求的输入,交给系统去执行。
Tool 本质上是一个带有签名的函数,并且这个函数具有明确定义的输入参数结构(schema)。它像是一个“插件”,可供模型在需要时主动选择并调用。
LangChain
LangChain 是一个开源的 Python LLM 应用开发框架,它提供了构建基于大模型的 LLM 应用所需的模块和工具。通过 LangChain,开发者开源轻松地与大型语言模型(LLM)集成,完成文本生成、问答、翻译、对话等任务。
langchain_core:封装langchain框架的核心抽象接口和最基础功能。作用:
- 不依赖第三方大模型;
- 提供核心模块定义;
- 避免循环依赖,便于更模块化的开发;
- 可用于构建更小型、定制化的 langchain 应用或库。
langchain:LangChain 的完整版库,集成各种 LLM、Agent、RAG 等功能模块。- 依赖:它依赖 langchain_core 作为底层;
- 功能更全:如 chain、memory、tools、加载器、向量存储等;
- 适合开发复杂业务逻辑或需要多个模型集成的场景。
从 LangChain 0.1.x 开始,官方将大部分功能拆分为多个库,如:
| 库名 | 功能 |
|---|---|
langchain-core | 核心抽象与接口 |
langchain | 完整框架,集成所有模块 |
langchain-community | 对社区模型和工具的集成 |
langchain-openai | 针对 OpenAI 的支持 |
langgraph | LangChain 的图式执行框架 |
安装
pip3 install langchain
案例
Prompt + Chain 示例:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain_openai import ChatOpenAI
prompt = PromptTemplate.from_template("写一首关于 {topic} 的诗")
# 使用 ChatOpenAI 替代 OpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.7)
chain = LLMChain(prompt=prompt, llm=llm)
print(chain.run({"topic": "秋天"}))
Agent 示例:
from langchain.agents import initialize_agent, load_tools
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(
tools,
llm,
agent="zero-shot-react-description",
verbose=True # 添加详细日志以观察思考过程
)
result = agent.run("中国的首都是哪?它距离南宁有多远?")
print(result)
LangServer
LangServer 是 LangChain 官方推出的一个服务框架,快速将 LangChain 应用部署为 RESTful API 接口。
安装:
pip3 install langserve[all]
实例
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
from langserve import add_routes
from fastapi import FastAPI
prompt = PromptTemplate.from_template("你是谁?回答:{name}")
chain = LLMChain(llm=OpenAI(), prompt=prompt)
app = FastAPI()
add_routes(app, chain, path="/demo")
启动服务
uvicorn app:app --reload --port 8000
ReACT
定义工具函数
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
from langchain_google_genai import ChatGoogleGenerativeAI
import os
import subprocess # 添加缺失的导入
@tool
def tool_nmap(ip: str) -> str:
"""
对目标IP执行 nmap 快速扫描
"""
try:
# 构建nmap命令:-Pn跳过主机发现,-F进行快速扫描
cmd = ["nmap", "-Pn", "-F", ip]
print("[Tool] 执行命令:", " ".join(cmd))
# 执行nmap命令,设置30秒超时
result = subprocess.run(cmd, capture_output=True, text=True, timeout=30)
# 返回扫描结果或错误信息
return result.stdout if result.returncode == 0 else result.stderr
except Exception as e:
return f"执行 nmap 扫描失败: {e}"
if __name__ == "__main__":
# 创建ReAct代理,集成LLM和nmap工具
agent = create_react_agent(
llm,
tools=[tool_nmap],
)
print("请输入 IP 地址开始扫描,或者输入 exit/quit 退出")
# 交互式循环,处理用户输入
while True:
user_input = input("请输入目标IP地址: ").strip()
# 检查退出条件
if user_input.lower() in ["exit", "quit"]:
break
# 调用代理执行扫描任务
result = agent.invoke({
"messages": [
# 系统角色定义 - 渗透测试工程师
{"role": "system", "content": "你是一名渗透测试工程师,帮助用户执行信息收集并返回结果。"},
# 用户输入
{"role": "user", "content": user_input},
]
})
# 输出扫描结果
print("扫描结果:")
print(result['messages'][-1]['content'])
当用户问:“3 乘 7 的结果是多少?”,模型识别这个问题与 multiply 工具相关,它会生成如下的调用请求
{
"name": "multiply",
"args": {
"a":3,
"b":7
},
type: "tool_call"
}
这个结构清晰地表示模型希望执行 multiply(3,7),系统负责执行这个调用,并将结果(21)返回给模型,最后形成自然语言回复。
- tool 调用由模型发起,由系统执行
- 系统执行工具调用后,将结果返回给模型
- 模型根据工具调用结果,生成最终回复。
一个工具调用,涉及到多次模型调用。
使用 Tool call 机制,实现一个 shell 命令执行助手。
输入:用户输入一段自然语言描述系统控制命令,例如 “查找 xxx.txt 文件”。
输出:执行命令的结果
模型根据用户输入,调用 shell 命令工具,执行命令,并返回结果。
- 执行 shell 命令的工具函数
from langchain_core.tools import tool
import os
@tool
def tool_shell(cmd: str) -> str:
"""执行 shell 命令"""
try:
print("[Tool] 执行命令:",cmd)
result=os.popen(cmd).read()
print(f"[Tool] 执行命令 {cmd} 成功,结果:{result}")
return f"执行命令 {cmd} 成功,结果:{result}"
except Exception as e:
return f"执行命令 {cmd} 失败:{e}"
langgraph agent 工具调用
- llm 是一个一问一答的模型,它无法完成端到端的工具调用(即输入问题,自动执行工具,并生成回答)
- 为了简化流程,我们使用 langgraph 的 agent 框架,实现端到端的工具调用。
pip install langgraph
from langgraph.prebuilt import create_react_agent
prompt="""
你是一个 shell 命令执行助手,请根据用户的问题执行命令
"""
agent=create_react_agent(
llm,
tools=[tool_shell],
prompt=prompt,
)
response=agent.invoke({"messages":[{"role":"user","content":"当前是什么系统?"}]})
Plan and Execute
在复杂任务面前,简单的工具调用往往力不从心:
- 任务复杂性:用户的需求可能涉及多个步骤,需要系统性规划
- 步骤依赖:后续步骤可能依赖前面步骤的结果
- 错误处理:执行失败时需要重新规划和调整
Plan and Execute(规划执行架构)模式是一种更高级的智能体架构,它将复杂任务分解为多个步骤,在执行过程中,根据执行结果调整计划。
Plan and Execute 模式的核心思想是:
- 将复杂任务分解为多个步骤
- 按顺序执行步骤
- 根据执行结果调整计划
ReACT vs Plan-and-Execute
ReACT(Reasoning+Acting)是一种简单直接的智能体模式:
用户输入 -> 思考 -> 行动(Acting) -> 观察结果 -> 循环
大模型的 tool calling 能力,可以实现 ReACT 模式。
ReACT 模式适合单步或少步任务。
Plan and Execute 对比 React 的差异是它可以重新规划。
如何实现复杂的 Agent 流程:
LangGraph 是一个强大的框架,可以用来实现复杂的 Agent 流程。
- Graph 就是图,图中的节点就是 Agent 的各个步骤;
- Node 就是图中的节点,节点是一个函数,每个节点可以有多个输入和输出,节点之间可以有边连接;
- Edge 就是图中的边,边可以有条件,根据条件决定是否执行;
- State 就是图中的状态,状态是图中的各个节点的输入和输出。
如何实现 Plan-and-Execute模式?
图中的节点:
- planer 节点,llm 驱动,输入是用户输入,输出是执行计划;
- agent 节点,react agent,负责执行子步骤,调用工具;
- replan 节点,llm 驱动,判断是否需要重新规划或者结束。
图中状态的转移 State
State 是图中的各个节点的输入和输出,LangGraph 中使用 TypedDict 来定义 State。
from typing_extensions import TypedDict
from typing import Annotated,List,Tuple
class PlanExecute(TypedDict):
input: str
plan: List[str]
past_steps: Annotated[List[Tuple],operator.add]
response: str
Plan-and-Execute核心组件:
状态定义
使用 TypedDict 定义智能体的状态:
from typing_extensions import TypedDict
from typing import Annotated,List,Tuple
class PlanExecute(TypedDict):
input: str #用户输入
plan: List[str] #执行计划步骤列表
past_steps: Annotated[List[Tuple],operator.add] #已执行步骤记录
response: str #最终响应
状态在整个执行过程中传递,记录任务进展。
计划生成器
输入:用户的任务描述输出:结构化输出,执行任务列表。
from pydantic import BaseModel,Field
class Plan(BaseModel):
"""执行计划"""
steps: List[str] = Field(
description="任务列表,应该按顺序执行"
)
planler_prompt = ChatPromptTemplate.from_messages([
("system","""
根据用户输入的任务,生成一个简单的步骤计划。
这个计划应该涉及单个任务,如果正确执行,将产生正确的答案。
不要添加任何不必要的步骤。最后一步的结果应该是最终答案。
确保每一步都要所需的信息 - 不要跳过步骤。
"""),
("placeholder","{messages}"),
])
planner = planner_prompt | llm.with_structured_output(Plan)
重规划器
当执行过程中遇到问题或需要跳转时,重规划器负责重新规划。
class Response(BaseModel):
"""最终响应"""
response: str
class Act(BaseModel):
"""下一步行动"""
action: Union[Response,Plan]=Field(
description="要执行的动作。如果需要响应用户,使用 Response。"
"如果需要进一步使用工具获取答案,使用 Plan"
)
replanner_prompt = ChatPromptTemplate.from_template("""
根据用户输入的任务,分析当前执行情况:
用户任务:{input}
原计划:{plan}
已执行步骤:{past_steps}
请分析:
- 如果某个步骤执行失败,请重新执行该步骤
- 如果需要补充新步骤,请补充计划
- 如果任务已完成,请使用 Response 返回结果
""")
执行器
执行器用于执行规划中的某一个规划。
输入:执行计划
输出:执行结果
tools = [tool_shell]
prompt = "你是一个 shell 命令执行助手,请根据用户的问题执行命令"
agent_executor = create_react_agent(llm,tools,prompt=prompt)
构建工作流图
使用 LangGraph 构建状态图
LangGraph 如何把各个组件组合成一个完整的 Agent 流程?
- 定义节点函数(设计点)
- 定义边和流程(连线)
定义节点函数
async def plan_step(state: PlanExecute):
"""制定初始计划"""
plan = await planner.ainvoke({"messages": [("user",state[input])]})
return {"plan":plan.steps}
async def execute_step(state: PlanExecute):
"""执行当前步骤"""
task = state["plan"][0] #取第一个未完成的任务
agent_response = await agent_executor.ainvoke(
{"messages": [("user",task)]}
)
return {
"past_steps": [(task, agent_response["messages"][-1].content)]
}
async def replan_step(state: PlanExecute):
"""重新规划"""
output = await replanner.ainvoke(state)
if isinstance(output.action, Response):
组装完整的工作流
workflow = StateGraph(PlanExecute)
# 添加节点
workflow.add_node("planner", plan_step) # 计划节点
workflow.add_node("agent", execute_step) # 执行节点
workflow.add_node("replan", replan_step) # 重规划节点
# 定义边和流程
workflow.add_edge(START, "planner") # 开始 -> 计划
workflow.add_edge("planner", "agent") # 开始 -> 计划
workflow.add_edge("agent", "replan") # 开始 -> 计划
# 条件边:根据重规划结果决定下一步
def should_end(state: PlanExecute):
if "response" in state and state["response"]:
return ENO # 任务完成,结束
else:
return "agent" # 继续执行
# 编译工作流
app = workflow.compile()
实战案例
让我们通过一个复杂的系统分析任务来展示 Plan-and-Execute 的威力:
task = """
1. 统计文件系统使用情况
2. 使用 python3 matplotlib 绘制柱状图,并保存为图片(1.png)。
命令的上下文可能比较多,你可以保存到临时文件,然后使用 head、tail 等命令查看结构
请确保有图片输出和文件输出,并告诉我输出了哪些结果文件。
"""
# 执行任务
result = await app.ainvoke({"input": task})
工具函数的改进
import subprocess
@tool
def tool_shell(cmd: str) -> str:
"""执行 shell 命令,并返回标准输出或错误信息"""
try:
print
result = subprocess.run(
cmd, shell=True
stdout=subprocess.PIPE,
stderr,subprocess.PIPE,
text=True
)
stdout = result.stdout.strip()
stderr = result.stderr.strip()
if result.returncode == 0:
if stdout:
return f"执行命令 {cmd} 成功,结果:{stdout}"
else:
return f"执行命令 {cmd} 成功,但标准输出为空。"
else:
return f"执行命令 {cmd} 失败,错误信息:{stderr}"
except Exception as e:
return f"执行命令 {cmd} 异常:{e}"
Supervisor模式
多智能体架构,从单一智能体到协作团队模式,构建可扩展的 AI 系统。
Plan and Execute 模式能够处理复杂的多步骤任务,但随着系统复杂度的增加,单一智能体面临新的挑战:
- 认知负担:单个智能体需要掌握太多领域知识
- 工具过载:过多的工具选择导致决策困难。
- 可扩展性:难以添加新功能而不影响现有逻辑
- 维护困难:复杂的单体架构难以调试和优化
因此,引入多智能体架构来解决这些问题。
多智能体系统通过将复杂任务分解给专门的智能体来解决这些问题。
多智能体架构具备如下优势:
- 模块化:独立开发、测试和维护多个智能体
- 专业化:每个智能体专注于特定领域,提升性能
- 控制力:明确定义智能体间的通信方式
- 可观测性:更容易追踪和调试系统行为
多智能体架构模式
根据智能体间的通信方式,可以分为如下几种架构:
- Single Agent 模式:单一智能体
- Network 模式:智能体间可以自由通信
- Supervisor 模式:中央调度器管理所有智能体
- Supervisor(Tool-calling)模式:将智能体作为工具调用
- Hierarchical 模式:多层级的管理结构
- Custom 模式:自定义的工作流模式
Supervisor模式
关键组件:
- Supervisor:调度其它 Agent 以及结构汇总
- Shell Agent:终端命令生成、执行与结果分析
- Python Agent:Python 代码生成、执行与结果分析
- Web Search Agent:网络搜索、信息获取与分析
Supervisor(Tool-calling)模式详解
在这种模式中,Supervisor 将其他智能体视为工具,通过工具调用机制来管理它们。
from typing import Annotated
from langgraph.perbuilt import InjectedState
@tool
def research_agent_too(
query: str,
state: Annotated[dict, InjectedState]
) -> str:
"""调用研究智能体进行网络搜索"""
response = research_agent.invoke({"messages":[("user",query)]})
return response["messages"][-1].content
@tool
def python_agent_tool(
task: str,
state: Annotated[dict,InjectedState]
) -> str:
"""调用Python智能体执行代码任务"""
response = python_agent.invoke({"messages":[("user",task)]})
return response["messages"][-1].content
# Supervisor 作为 ReAct 智能体
supervisor = create_react_agnet(
model=llm,
tools=[research_agent_tool,python_agent_tool],
prompt="You are a supervisor. Use the available agent tools to complete tasks."
)
Hierarchical模式
多层级管理架构
Hierarchical 模式是 Supervisor 模式的扩展,允许创建 supervisor 的 supervisor,形成树状管理结构。
示例:
# 创建专业团队
data_team = create_supervisor(
model=llm
agents=[python_agent, shell_agent, file_agent],
prompt="管理数据处理相关的智能体团队",
name="data_team_supervisor"
)
research_team = create_supervisor(
model=llm
agents=[search_agent, analysis_agent, summary_agent],
prompt="管理研究和分析相关的智能体团队",
name="research_team_supervisor"
)
# 顶级 Supervisor
top_supervisor = create_supervisor(
model=llm,
agents=[data_team,research_team],
prompt="协调各专业团队,处理跨领域复杂任务",
name="top_supervisor"
)
案例
实战练习:使用多智能体架构,组织 Shell Agent 和 Web Search Agent。
# 复杂任务:搜索并管理 Android CVE 信息
ans = supervisor.invoke({
"messages":[
{
"role":"user",
"content":"搜索最新的 5 条 Android CVE,并整理到文件 Android-CVE.md,并为每一个 CVE 创建一个 markdown 文件,最后使用 matplotlib 绘图统计 CVE 对应的 CWE 情况",
}
]
})
Web Search接口
哪里寻找一个稳定可靠的搜索接口?
推荐使用 Tavily,这是一个免费的搜索接口,可以提供稳定可靠的搜索结果。
- 申请 Tavily API Key
- 安装 langchain-tavily 包
- 使用 TavilySearch 接口
from langchain_tavily import TavilySearch
import os
os.environ["TAVILY_API_KEY"] = "tvly-......."
web_search = TavilySearch(max_results=3)
print(web_search.invoke({"query": "kali 最新版本"}))
Supervisor 模式核心组件
专业化智能体
每个智能体专注于特定领域:
# 研究智能体 - 负责网络搜索
research_agent = create_react_agent(
model=llm,
tools[web_search],
prompt=(
"You are a research agent.\n\n"
"INSTRUCTIONS:\n"
"- Assist ONLY with research-related tasks, DO NOT do any math\n"
"- After you're aone with your tasks, respond to the supervisor directly\n"
"- Respond ONLY with the results of your work, do NOT include ANY other text."
),
name="research_agent",
)
# Shell 智能体 - 负责系统命令执行
shell_agent = create_react_agent(
model=llm,
tools=[tool_shell],
name="shell_agent",
prompt=(
"You are a shell agent.\n\n"
"INSTRUCTIONS:\n"
"- Assist ONLY with research-related tasks, DO NOT do any math\n"
"- After you're aone with your tasks, respond to the supervisor directly\n"
"- Respond ONLY with the results of your work, do NOT include ANY other text."
)
)
中央调度器负责任务分发:
supervisor = create_supervisor(
model=llm,
agents=[shell_agent,research_agent],
prompt=(
"You are a supervisor managing three agents:\n"
"- a shell agent. Assign shell-related tasks to this agent, do not exec python.\n"
"- a research agent. Assign research-related tasks to this agent, for web search.\n"
"Assign work to one agent at a time, do not call agents in parallel.\n"
"Do not use shell agent for Python tasks. \n"
"Do not do any work yourself."
),
add_handoff_back_messages=True,
output_mode="full_history",
).complie()
create_supervisor 函数
LangGraph 提供了便捷的create_supervisor函数:
from langgraph_supervisor import create_supervisor
vupervisor = create_supervisor(
model=llm, # 用于决策的LLM
agents=[agent1,agent2,agent3], # 管理的智能体列表
prompt="supervisor 的系统提示词", # 调度策略
add_handoff_back_messages=True, # 是否添加handoff消息
output_mode="full_history", # 输出模式
).compile()
核心参数说明:
model:用于决策的大语言模型agents:需要管理的智能体列表prompt:定义 Supervisor 的行为策略add_handoff_back_messages:是否在智能体完成任务后自动添加回传消息
MCP协议开发
MCP(Model Context Protocol,模型上下文协议),MCP 是一个开放协议,允许大语言模型与外部工具和服务进行安全、结构化的交互。
核心思想:让大语言模型能够调用外部工具,扩展其能力边界。统一接口协议,开放更加方便快捷。
MCP 架构
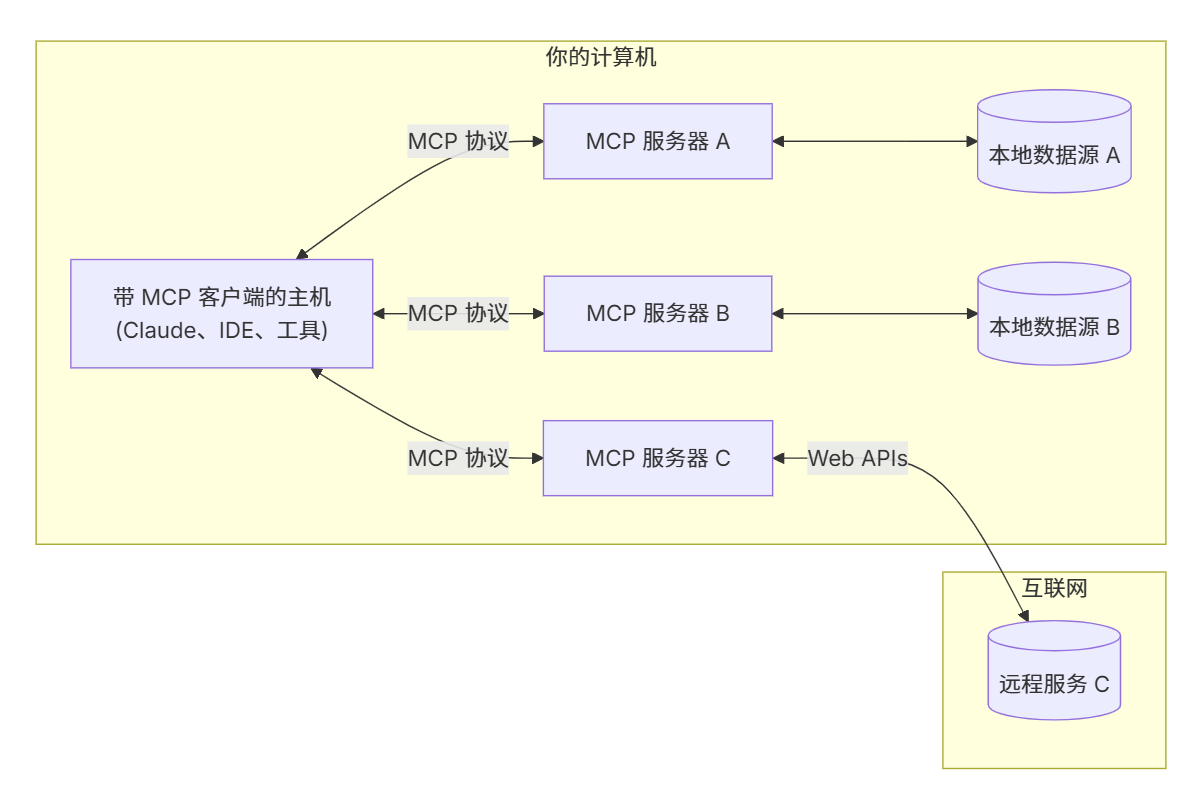
- MCP 客户端:与大语言模型集成
- MCP 服务器:提供工具和服务
- 传输层:支持 stdio、HTTP、WebSocket 等
MCP 工作流程
MCP 开放有哪些方面?
- 开发 MCP 服务(给大语言模型提供工具)
- 开发 MCP 客户端(调用 MCP 服务,LangChain)
在 MCP 开发中最重要的就是开发 MCP 的服务。
FastMCP
实例
创建简单的提供基础数学运算的 MCP Server。
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("Math")
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
@mcp.tool()
def multiply(a: int, b: int) -> int:
"""Multiply two numbers"""
return a * b
if __name__ == "__main__":
mcp.run(transport="stdio")
通过 Cursor 配置 MCP 来连接连接。